xAIgent.
Content Key Phrase Extraction Made Easy! |
|
Text, Email, HTML ... from
any Text of any Subject domain, the xAIgent RESTful API
Automatically turns content of any subject matter into
lists of Key Phrases along with their relative rankings
including highlighted examples of how
those key terms have been used specifically within the
target document. Available for English, French, German,
Japanese, Korean and Spanish - xAIgent is ready to turn
your content into gold.
Ideal for - web text extraction,
search optimization (SEO), intelligent text mining,
refined search, advanced terror detection, knowledge
management (KM), information retrieval (IR), semantic
web development, indexing, categorization, cataloguing,
inference engines, document management, portal services,
speed reading, trend analysis, automatic document
tagging, weblog tagging and more...
|
| |
|
|
|
|
|
Overview |
|
xAIgent is an
agnostic content summarization technology that
automatically parses news, information, documents... any
text into relevant and contextually accurate key term summaries.
|
|
Uniquely
positioned as a restful service, xAIgent can be
immediately deployed to consume documents of any length
and of any subject matter - distilling that information
into precise, contextual, personally meaningful
information - Automatically, presented in keyword and
key phrase summaries.
|
| |
The xAIgent’s
unique, patented technology delivers precise content
summaries from any subject domain automatically -
without training - without human intervention. |
| |
Contextual |
|
A unique feature
of the xAIgent technology is the ability to summarize
content by showing how keywords and key phrases are used
in context of a document allowing for accurate
definition of terminology and use of the subject.
Resulting summaries provide unparalleled levels of
subject relevance. Analyzing collections of documents
with contextual relevance is now possible.
|
|
|
|
In part,
Contextual Accuracy is attained because xAIgent does not
rely upon Bayesian or Heuristic (comparative list)
approaches, thus allowing for a purely objective
understanding. The objectivity is driven by the
underlying patented technology that understands the
composition of human language and applies advanced
linguistic AI based composition to derive the key terms
from any text regardless of subject domain.
|
|
|
|
|
Relevant Information |
|
|
|
By design the xAIgent is an
objective provider of content summaries in contrast to
traditional human influenced subjective summary
approaches or approximated systems using Bayesian and
Heuristic approaches. Statistically proven, the patented
technology used in the xAIgent is 85% to 93% accurate
across all subject domains. The ability to quickly
discern relevant and meaningful news and information -
in personal context - is the corner stone of the xAIgent
process.
|
| |
What is a
Key Phrase |
|
For example, Authors are
often requested
to provide a list of key words for their articles. We
call these key phrases, rather than key words, because
they are often phrases of two or more words, rather than
single words. A key phrase list is defined as a short
list of phrases (typically five to fifteen phrases) that
capture the main topics discussed in a given document.
Automatic key phrase extraction is defined as the
automatic selection of important, topical phrases from
within the body of a document. Automatic key phrase
extraction is a special case of the more general task of
automatic key phrase generation, in which the generated
phrases do not necessarily appear in the body of the
given document.
|
| |
Examples of
where Key Phrases are used |
|
Curating Metadata |
|
Content and
Document Management Systems |
|
Creating Document
Highlights |
| Creating an Index |
|
Search Engine
Refinement |
|
Research
Optimization |
| |
|
|
| |
|
|
Many researchers believe that
metadata is essential to address the problems of
document management. Metadata is meta-information about
a document or set of documents. There are several
standards for document metadata, including the Dublin
Core Metadata Element Set (championed by the US Online
Computer Library Center), the MARC (Machine-Readable
Cataloging) format (maintained by the US Library of
Congress), the GILS (Government Information Locator
Service) standard (from the US Office of Social and
Economic Data Analysis), and the CSDGM (Content
Standards for Digital Geospatial Metadata) standard
(from the US Federal Geographic Data Committee). All of
these standards include a field for key phrases
(although they have different names for this field).
|
| |
|
|
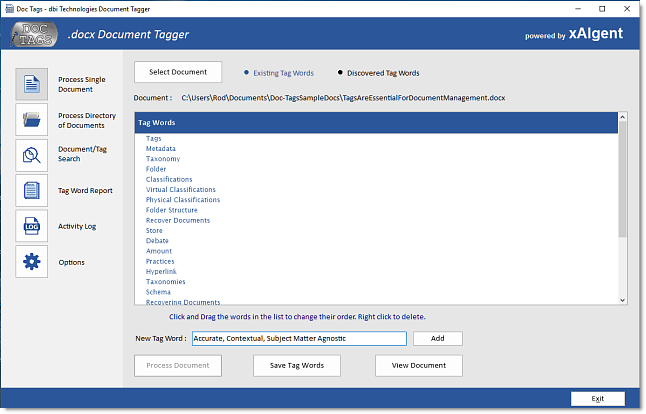
Content and Documents being
added to a management system must be identified
by the subject matter (key phrases) for accurate retrieval. Unless you're the author of that
content / document how do you know what the content
speaks to? Integrating xAIgent into a Content / Document
Management System provides accurate, contextual and
objective subject matter key terms which are invaluable
for Cataloging, Indexing and for Retrieving the stored
information accurately.
|
|
Many business
rules direct that authors include Document Tags /
Summary terms, which are used when adding the content
into the system. What happens when the author has not
provided the key terms? Or, what if the document was
authored prior to the established business rules being
in place? The same holds true in context of the
Semantic Web and adhering to those structures and
publishing guidelines. xAIgent becomes a critical
tool in the publishing and retrieval of contextually
accurate information.
|
| |
|
|
When we skim a document, we
scan for key phrases, to quickly determine the topic of
the document. Highlighting is the practice of
emphasizing key phrases and key passages (e.g.,
sentences or paragraphs) by underlining the key text,
using a special font, or marking the key text with a
special colour. The purpose of highlighting is to
facilitate skimming. Automatic key phrase extraction can
be used for highlighting and also to enable
text-to-speech software to provide audio skimming
capability.
|
| |
|
|
An alphabetical
list of key phrases, taken from a collection of
documents or from parts of a single long document
(chapters in a book), are used for creating indexes.
|
| |
|
|
|
|
Using a search engine is often
an iterative process. The user enters a query, examines
the resulting hit list, and modifies the query, then
tries again. Most search engines do not have any special
features that support the iterative aspect of searching.
One approach to interactive query refinement is to take
the user's query, fetch the first round of documents,
extract key phrases from them, and then display the
first round of documents to the user, along with
suggested refinements to the first query, based on
combinations of the first query with the extracted key
phrases.
|
| |
|
|
|
Relevant
information is critical for the success of any business
and providing relevant information in the right context
is what gives an organization an ultimate competitive
advantage. Rather than working through traditional, time
consuming, iterative research processes - engage the
Text Mining power of xAIgent to empower information
workers with relevant and meaningful results, quickly
and accurately.
|
| |
| Next,
the
Technical Aspects of xAIgent... click
here |
|
| |
|
|
 |
|
|
| |
| Yesterday will the
be the last day you re-read a document to enter it into
an Enterprise Content Management System. |
| |
| |
 |
|
|
|
